

In this blog post, we explain the concept of service assurance in the telecom industry.
However, the same applies to all digital service providers – the organizations that provide digital services to business and residential customers (consumers), such as cloud service providers, data center infrastructure service providers, Internet of Things (IoT) connectivity and device providers, managed services providers (MSPs), etc.
What is Service Assurance in Telecom?
Service Assurance is the set of activities aimed at guaranteeing the quality of products provided to end customers. It encompasses all necessary actions needed to ensure the quality of telecom services, which is generally regarded in terms of service level agreements (SLA) signed with customers—the promise given by the product sold to the customer.
A telecom service is assured by monitoring a service’s health and performance and activating assurance processes when service degradation is detected. Since every service relies on underlying technical capabilities and resources (network connectivity, voice platform services, IPTV platform, etc.), monitoring services essentially means monitoring technical resources like network devices, service platforms, virtualization platforms, etc., and taking actions to prevent future problems or fix existing problems with resources.
Service assurance is concerned with the quality perceived by the customer, the SLA, and the general customer experience with using the service. Assurance processes focus on prioritizing the fixing of technical issues that directly affect services and informing customers about the service degradation and what is being done to fix it.
The Importance of Service Assurance in Telecom
We live in an exciting time of cultural shift from network-centricity to service-centricity in telecoms. This is thanks to increased competition among telecoms and the availability of technology to all telecom organizations, resulting in the understanding that the advantage of a telecom is not in the technology it uses or the sheer size of its infrastructure, but rather the service excellence it provides. Customers today naturally lean towards telecoms that provide the best price/performance ratio, and since the prices are converging rapidly, the only differentiator that remains is the quality of service a telecom provides.
It is quite logical to understand that any telecom service delivers a specific value proposition to satisfy the needs of customers by transferring data, content, and application functionalities using internet/digital technologies. If a telecom does not deliver on its promise, it cannot charge for it and thus create value for itself.

Key Benefits of Telecom Service Assurance
When service assurance moves from a reactive, network-element focus to an end-to-end, service-centric discipline, the payoff is felt well beyond the NOC. Below are the core business benefits that operators consistently report when they deploy a modern, automated assurance stack.
1. Lower Customer Churn Through Superior Technical Performance
Thanks to continuous KPI/KQI monitoring, automated anomaly detection and closed-loop remediation, operators can sustain ultra-high service availability and keep mean-time-to-restore (MTTR) in the minutes—not hours—range. Fewer dropped calls, buffering events or SLA breaches translate directly into lower churn, especially in hyper-competitive 5G and FTTH markets where switching barriers are low.
That technical excellence pushes churn below already‑low segment averages: an Analysys Mason 2024 study reports only 5.4 % annual churn for converged fixed‑mobile bundles versus 7.5 % (mobile‑only) and 8.8 % (fixed‑only) offers.
2. Word-of-Mouth Growth From Satisfied Users
Customers who experience “it just works” connectivity become informal brand advocates. Positive Net Promoter Score (NPS) feedback spreads rapidly through social media and peer forums, amplifying marketing reach at zero cost and accelerating subscriber acquisition in green-field FTTH roll-outs or new 5G FWA footprints.
3. Higher ARPU Via Premium Pricing and Advanced SLA Schemes
With provable, near-real-time service quality data, operators confidently offer differentiated gold/platinium tiers, ultra-low-latency network slices, or enterprise SD-WAN bundles backed by stringent SLAs and performance credits. Reliable assurance reduces the risk-buffer that finance teams build into price models, enabling both higher list prices and improved margin retention.
4. Reduced Operational Costs Through Optimized Assurance
Automated root-cause analysis, ticket correlation and proactive customer-impact prediction slash call-center volumes and truck rolls. Fewer trouble tickets per thousand subscribers (TTS) free field engineers for higher-value work and cut OPEX tied to legacy OSS silos, manual swivel-chair operations and redundant NMS licences.
5. Healthier Workplace and Reduced Employee Turnover
An assurance platform that filters noise, ranks alarms by business impact and suggests remediation steps turns night shifts in the NOC or service desk from fire-fighting to oversight. Lower cognitive load, clearer KPIs and fewer on-call emergencies improve staff well-being, reducing burnout-driven churn in hard-to-replace network and OSS specialists.
6. Faster Time-to-Market and Agile Service Lifecycle
Because KPIs and customer-impact analytics are wired into CI/CD pipelines and digital marketplaces, new services (e.g., IoT slices, edge-cloud offerings) can be rolled out, A/B-tested and optimized in weeks rather than quarters. Assurance insights close the feedback loop between product, engineering and operations, accelerating innovation while keeping quality intact.
Key Elements for Implementing Effective Telecom Service Assurance
To turn the principles of service assurance into real-world results, operators need a tightly integrated stack that covers the full life cycle—from raw network data to closed-loop remediation and business-level insights. The pillars below represent that stack’s must-have capabilities.
1. Calculate Network Health and Its Performance Impact on Services
The assurance platform must continuously ingest fault and performance telemetry from every network domain, calculate composite “network health scores” in real time and map those scores to the specific services, slices or VLANs they support. Only when network KPIs are expressed in a service context can Ops teams focus on what truly matters to customers rather than chasing element-level alarms in isolation.
2. Measure Customer-Perceived Quality via Key Quality Indicators (KQIs)
Beyond traditional KPIs such as latency or packet-loss, KQIs capture what end users actually experience: video start-time, MOS, web-page load, transaction success rate, etc. Converting raw data flows into these higher-level KQIs—and updating them every few seconds—lets operators detect degradations before customers raise a ticket.
3. Directly Correlate Service Metrics with Underlying Resource Health
An automated correlation engine must link a dip in a KQI to the precise router interface, fiber span or virtual function that caused it. Contextual enrichment (topology, maintenance schedules, change logs) is critical, reducing false positives and accelerating mean-time-to-identify (MTTI).
4. Trigger Remediation Workflows to Fix Degraded Services Fast
Once the root cause is clear, the platform should launch pre-built or AI-generated remediation playbooks—rerouting traffic, scaling VNFs, rolling back config changes or opening a trouble ticket with the correct priority and customer impact tag. Closed-loop execution keeps MTTR in the minutes range and eliminates the swivel-chair hand-offs that plague legacy OSS stacks.
5. Produce Actionable Reports and Analytics to Drive Continuous Improvement
Real-time dashboards let NOC teams act immediately, while historical analytics reveal chronic weak spots, SLA compliance trends and ROI of previous improvements. Exporting this data to finance and product teams turns assurance from a cost center into a revenue-protection and upsell enabler.
6. Embed AI-Driven, Closed-Loop Automation for Zero-Touch Operations
Machine-learning models can spot anomalies the moment they diverge from learned baselines and recommend (or execute) fixes without human intervention. Combining predictive analytics with policy-based automation allows operators to move from reactive firefighting to proactive, intent-based operations. Such closed‑loop, “zero‑touch” principles are precisely the goal of the ETSI Zero‑touch network & Service Management (ZSM) initiative.
7. Unify Data Through a Common Service Model
A canonical information model—aligned with TM Forum ODA or ETSI ZSM—ensures that alarms, performance metrics, topology and customer data share the same vocabulary. This semantic consistency is the foundation for reliable correlation, accurate impact analysis and seamless API integration with inventory, ticketing and orchestrators.
Telecom Service Assurance vs. Service Monitoring: What’s the Real Difference?
Very often, discussions about service assurance lead to confusing service assurance with service monitoring. We will try to make a clear statement about the differences.
Service monitoring is concerned with collecting network fault and performance data and combining them to determine the state of the service being provided to customers. For instance, imagine dedicated internet access service. It is provided by a CPE (office router), an uplink from the CPE to an access device (say an ethernet switch), and then the uplink from the access switch to the core of the network that enables traffic between the global internet and the customer behind the CPE.
Now, the service is monitored by collecting all alarms and performance data from the CPE, access device, links, and the core of the network. The collected data are combined in a specific way defined by the service model – the topic we investigate in detail in our blog post “Telecom Service Assurance: A Data Modelling Perspective.”
One calculates a number of Key Performance Indicators (KPIs) and a set of Key Quality Indicators (KQIs) that provide an indication of the service’s health and performance. KPIs are compared against predefined Service Level Objectives (SLOs, components of SLA definition) to determine if the SLA is violated or not. KQIs indicate the level of degradation and can be used to trigger alarms for network and service engineers to alert them that a customer is suffering from degraded service.
The process just described relates to Service Monitoring. And this is just the first step, since any detected service degradation or outage must initiate some kind of remediation—service assurance process. In general, Service Monitoring is a subset of Service Assurance.
Core Functions of Service Assurance in Telecom
Perhaps the best way to introduce service assurance is by using TM Forum vocabulary. The functional map turns out to be very illustrative, and thus, we will use aggregated functions that belong to the service domain and assurance vertical.
Service Quality and Performance Management
Service Quality and Performance Management is the set of functions that are concerned with monitoring customer service functioning and managing service degradation alarms. Essentially, there are three functions:
- Service Quality and Performance Supervision – the function that is concerned with monitoring service performance data and comparing service performance indicators against established SLOs.
- Service Quality and Performance Repository Management – the function encompasses various elements like service performance data collection and reporting, as well as service quality collection and monitoring. An important aspect of this function is defining the monitoring model. This means the function deals with service KPIs, KQIs, SLOs, and associating resource data with the model. Finally, it includes reporting and notifying people and applications related to service problem remediation.
- Service Performance Management - the function concerned with daily service performance planning, which may result in daily network adjustments required to fulfill target performance.
In a way, this set of functions is concerned with detecting degradation, notifying, and reporting.
Service Problem Management
Service Problem Management is responsible for handling service degradations and outages. This is the surgical part of the assurance that must find the cure for the service problem. Within this group, one can distinguish the following functions:
- Service Problem Resolution – this is the set of functions aiming to undertake remediation activities and restore service operation to the normal state. The remediation includes reconfigurations, temporary workarounds, and on-the-field activities like replacing faulty equipment. This function is also concerned with diagnosing issues, analyzing actions taken, generating operational and management reports, and managing escalations.
- Service Problem Repository Management – the function concerned with managing the lifecycle of Service Trouble Tickets. It deals with undertaking automated corrective actions, device configuration actions needed to ensure all commercial service features are fulfilled, as well as receiving, reporting, and proper ticket management (assignment, coordination, escalations, etc.).
- Service Trouble Analysis – the function concerned with identifying the root causes of service issues through tests, inventories, historical data, and workforce interventions, interpreting results to determine necessary actions.
- Service Trouble Tracking and Lifecycle Management – the function that oversees the lifecycle of service troubles, ensuring efficient management and resolution, particularly during mass outages.
- Service Problem Policy Management - the function of assurance that designs and defines actions and rules for managing service problems, determining the best solutions based on urgency, impact, and priority levels.
The following figure illustrates the functions within the TM Forum's core frameworks:
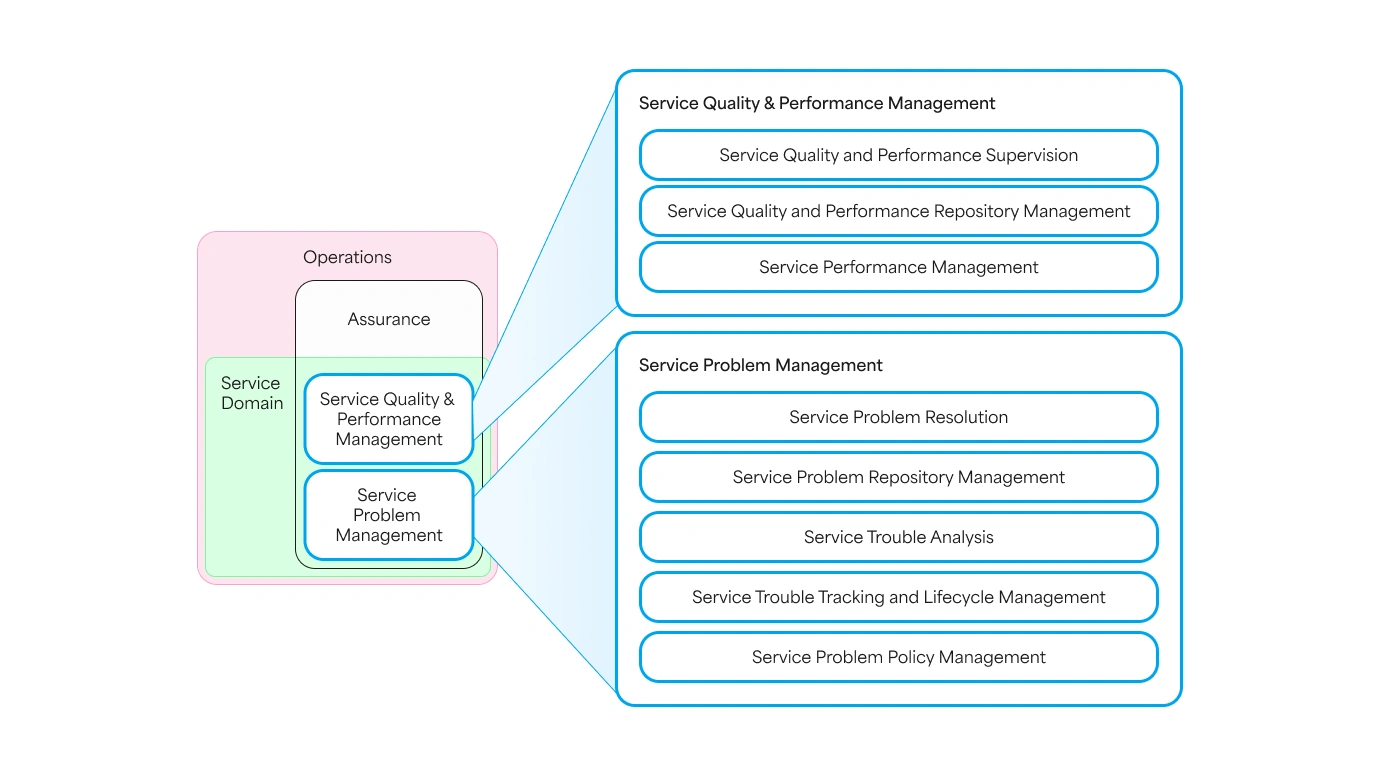
Service Assurance functions in TM Forum's core frameworks
Telecom Service Assurance Applications
TM Forum functions are a well-designed guide to all the activities of assurance, but one is always interested to understand which applications take part in executing those functions. In the following sections, we will introduce only the most important applications currently recognized as part of classical telecom OSS.
Product and Service Catalog, Service Inventory
Detecting service degradation or outage can only be properly executed by correctly correlating network (resource) alarms and performance data with service definitions. One must know what resources provide what services and to which customers. Therefore, service assurance begins with product and service catalogs that define how services are mapped to resources and the service inventory, which is the actual registry of all these mappings for all customers and sold products. Establishing the catalogs and service inventory is the groundwork for service assurance.
Proactive Monitoring and Fault & Performance Management
Assurance starts with service quality and performance management. However, measuring any service performance or quality starts with well-tuned network fault and performance management systems. Service performance is evaluated by assessing various KPIs and, more importantly, KQIs. Often, more direct measurements are involved, such as using software or hardware probes to determine end-to-end technical performance parameters like delay and jitter. The final result of this service-oriented monitoring is the foundation for identifying affected services and customers.
Service Degradation Detection with Monitoring Systems
Detection of degraded services, as well as individual, local, or global service outages, relies on mechanisms of service-aware fault and performance management systems. These systems directly map network alarms and performance degradations to services and customers.
This allows for Service Impact Analysis (SIA), which immediately determines all the services impacted by any faulty element of the network. SIA can tell you who is impacted, but it cannot tell you how bad it is.
For this reason, there are other mechanisms like Service Quality Management (SQM). SQM essentially calculates Key Quality Indicators (KQIs) for each element of the service model and uses the service model tree to determine the level of service degradation at any time. This way, one can determine the overall level of service quality as defined by the service model and trigger alarms and external tickets when service quality is degraded.
Finally, the most important part is comparing KPIs and KQIs to agreed SLA parameters, called Service Level Objectives (SLOs). Any deviation from predetermined service levels must be reported, and engineers as well as the front office should be alerted. Each SLO breach usually triggers a consequence, which is executed manually or automatically by initiating predefined policies like penalty discounts, etc.
Interaction With Trouble Ticketing System
Assurance management systems must have a strong interaction with the end customers and the telecom’s field force. For this purpose, all assurance systems must be integrated with the trouble ticketing systems and workforce management systems. The goal is to be capable of correlating customer technical complaints with technical alarms and ensuring all reported technical issues are handled within the assurance system. On the other hand, customer-triggered tickets must be aligned with internal workforce tickets when field activity is required to fix the technical problem the customer is experiencing.
Assurance Orchestration
Customers have no benefit from engineers detecting the problem unless they fix it fast. The good thing is that there is a set of typical issues and corresponding remedies, following the Pareto principle of several well-defined scenarios covering 80% of all complaints. An important element of well-designed assurance systems is the ability to automatically trigger and orchestrate complex remediation activities for well-known scenarios by using business process orchestration with embedded remediation actions (diagnostic scripts, device reconfigurations, etc.)
Service Performance Optimization
Reacting to pending or existing problems with services is great, but it is more important to prevent issues from happening in the first place. This is why the analysis of service degradation, network issues, and network performance are combined to detect structural deficiencies in the network setup, capacity outages, error-prone equipment, and other elements that ultimately affect service quality. This analysis is used to execute the daily optimization of network performance, replace parts of the network that have the highest chance of causing problems, and take other actions that minimize the chance of underperforming services.
Customer Experience Management
Assurance of services is ultimately part of Customer Experience Management (CEM) systems. These are complex applications that track, analyze, and improve interactions and experiences with customers across all points of contact: web, social networking, chatbots, call centers, service GUIs etc. CEM systems are usually well-integrated with monitoring/assurance systems as the service performance and integration is an important part of customer experience management and can significantly influence how telecoms interact with their customers.
Top Challenges in Implementing Telecom Service Assurance
The assurance concepts presented up to now depict an ideal picture of the world. Unfortunately, telecoms rarely implement assurance as described because there are many obstacles to it. The list is really long, and we will list only the most important ones:
Lack of Service Catalogs
This is very common as telecoms usually focus on product specification, and many of them have not yet evolved to design a proper service specification.
SLA Definitions are Not There
Service assurance should be capable of detecting SLA breaches, but many telecoms still do not have properly set SLAs and SLOs in their product/service catalogs to make this possible.
Lack of Service Inventory
Many telecoms still do not have properly defined, populated, and synchronized inventory, which makes service assurance almost impossible to execute.
Complex ICT Infrastructure Without Resource Inventory and Umbrella Monitoring
Yet another obstacle is the lack of a proper network inventory and centralized monitoring of all portions of the network. Without this, service management is a mission impossible since services rely on resources, and the mapping must be there to make things work.
Large Volumes of Data
Calculating KPIs and KQIs is a challenge as there are millions of performance metrics that must be collected and evaluated. However, with proper computing resources and well-implemented integrations, this challenge is easily overcome.

The Future of Telecom Service Assurance
The future of service assurance is influenced primarily by new network architectures, demand for the introduction of new innovative services at a faster pace, and new technologies that allow us to address these challenges. The new TM Forum ODA architecture addresses the flexibility and speed of introducing new services and new channels of communication with customers, and assurance systems must follow the same architecture. Monitoring systems must be capable of supporting new network technologies like 5G, SD-WAN, self-organizing networks (SON), as well as cloud-based services that are being provided to telecom customers.
A great help in managing this whole set of new complexities is promised by emerging machine-learning technologies and generative AI, which can better manage customer demands, experience, and, most importantly, automate service performance optimization and troubleshooting.
UMBOSS as a Service Assurance solution
In this blog, we have scratched the surface of service assurance, and there are many more blog posts that will extend this discussion. UMBOSS is constantly implementing new features of service assurance, as it has the umbrella monitoring and service inventory capabilities necessary to execute proper service assurance. UMBOSS’s service impact analysis, customer and service awareness, troubleshooting toolsets, automations, and assurance orchestration module allow UMBOSS to seamlessly integrate into any telecom’s OSS environment, providing an efficient tool for improving end-customer satisfaction with advanced assurance capabilities.
Have any questions? Want to learn more? Get in touch and let us know how we can help. Send us a message or book a demo today.
Frequently Asked Questions (FAQ)
What is network service assurance in telecom?
Network service assurance is a discipline that continuously monitors end-to-end service quality, analyzes KPI/KQI data in real time, and automatically remediates faults to keep every live service within its SLA. By tying network events to customer impact, it ensures high availability and a consistent user experience.
What is the role of service assurance in telecom?
Service assurance acts as the “healthcare system” for telecom services: it detects degradations early, pinpoints the root cause, triggers or recommends fixes, and reports on service quality. This minimizes downtime, protects revenue, and boosts customer satisfaction in competitive 5G, FTTH and enterprise markets.
What is the difference between service assurance and service fulfillment?
Service fulfillment is all about turning up new services—ordering, provisioning, and configuring them so they go live. Service assurance takes over once those services are active, continuously monitoring and maintaining performance, detecting faults, and ensuring SLAs are met throughout the service lifecycle.
How does AI enhance telecom service assurance?
AI and machine learning spot anomalies that slip past static thresholds, predict impending failures from subtle pattern changes, and automate root-cause analysis. They can even launch closed-loop remediation workflows, cutting mean-time-to-identify (MTTI) and mean-time-to-restore (MTTR) from hours to minutes.
What tools are used for telecom service assurance?
Operators rely on integrated “umbrella” OSS platforms such as UMBOSS, complemented by fault and performance managers, active probes, topology inventories, log/trace analytics, AIOps engines, and workflow orchestrators. Together, these tools provide full visibility and automation across multi-vendor, multi-domain networks.









