

Network fault management in telecom represents a critical operational framework that ensures Communication Service Providers (CSPs) maintain optimal network health while delivering exceptional quality of service to their subscribers. In this blog, we expand our discussion from our previous post, “What is Network Monitoring?", and delve deeper into its most important element – Network Fault Management.
For telecom operators, fault management serves as the backbone of network assurance, directly impacting revenue protection, customer satisfaction, and regulatory compliance. As we will see, it is a process concerned with detecting and fixing problems within the network, but even more importantly, preventing problems from occurring in the first place
What is Fault Management in Telecom Networks and Why It is Important?
Fault management in telecom networks is a specialized discipline within network operations that focuses on maintaining service reliability and quality for Communication Service Providers (CSPs).
A network fault is a condition in which the network is not working properly or as designed, and consequently, is not providing or will soon stop providing network (connectivity) services. Network faults are inevitable, and various factors can contribute to their occurrence. These factors include human errors (such as configuration mistakes), device failures, manufacturer software/firmware issues, and mechanical damage such as cable breaks, signal interference, poor connectors, or power outages. Network administrators deal with these errors almost daily. However, for business operations, it is crucial to address these issues promptly and consider systems and mechanisms to prevent network faults from arising.
In the telecom industry, fault management is particularly critical for CSPs as it directly impacts Service Level Agreements (SLAs), Quality of Experience (QoE), and financial performance. Modern telecom operators must maintain stringent SLA requirements, often guaranteeing 99.9% or higher uptime to avoid significant financial penalties.
The system continuously monitors key performance metrics including Mean Time To Repair (MTTR), Mean Time Between Failures (MTBF), and overall network downtime to ensure optimal service delivery.
The very purpose of network fault management is to manage faults. Therefore, network fault management involves detecting such conditions and executing the processes needed to fix them and establish a correct network operational state. When possible, fault management aims to detect pending faults and apply measures to prevent them from occurring altogether.
Network fault management is a pivotal function of every network management organization as it facilitates one of their essential roles: ensuring the network works properly with minimal disruptions and outages. Moreover, it is crucial to all network users (the organization's customers), who enjoy seamless and reliable network services thanks to this function, often without being aware of it. IT organization managers should emphasize the importance of network fault management from the internal organization’s point of view and from the end user/customer perspective.
What is The Difference Between Event, Alarm/Alert and Fault?
Whenever there is a discussion about fault management among newcomers to the intriguing field of network management, a common confusion arises surrounding terms that are often used interchangeably, though they shouldn't be.
All elements and functions of the network constantly generate event records, or simply events. These events are most frequently represented by SNMP traps/informs and syslogs, the two most commonly used network monitoring protocols. When a faulty condition occurs, the network will generate events that are directly related to the faulty condition. These events directly or indirectly describe many aspects of the fault and are called alarms or alerts. Therefore, alarms/alerts are events (data records) representing faults. Simply put, alarms are representations of a fault in a fault management system. A single fault usually generates multiple alarms.
There is often a discussion about the use of the terms alarm and alert. Essentially, these terms are interchangeable. However, alert is more often used to describe a notification about a pending fault, while alarm definitely represents a fault that already exists. Alarm is a commonly used term in network management.
Now, is it "alarm management" or "fault management"? Because the question is, what are we managing here? The answer is both. We are managing the lifecycle of the alarm (data representation of a fault) with the purpose of resolving the fault it represents. Management here means detecting, tracking, updating, journaling, and most importantly enacting – doing something to fix the fault. Therefore, both alarm and fault management are correct terms, and they can be used interchangeably. We will intentionally do so.

Key Components of a Fault Management System
Network fault management occurs in a software and hardware component called the network fault management system.
The first component of such a system is a set of event collectors. These are software components that collect events using different types of monitoring and various protocols. Once events are received (collected), event processors take over. Their purpose is to filter events so that only alarms are retained.
Events are filtered based on the values of individual parameters contained within the event itself (e.g., from which EMS they arrived, what is the problem description, problem category, severity, etc.). Once events are filtered, it is necessary to map the parameters from the event to the alarm parameters. This is the moment when an alarm is “born”, and its lifecycle begins.
Event processors also execute deduplication – a function that removes multiple event records corresponding to a single alarm. For instance, a single network event can cause the network device to send both an SNMP trap and a syslog message. These both describe the same event, and the deduplication mechanism will remove duplicates of the same event/alarm record.
After this, the alarm management function takes over. It executes all high-level alarm processing functions such as enrichment, correlation, suppression, generation of synthetic alarms, root-cause analysis, remediation automation, etc. (see “The Fault Management Process” section below). It is also responsible for alerting and notifying engineers using a GUI or other methods. The purpose of this component is the full lifecycle management of an alarm/fault, taking full control over history records related to alarm handling (alarm journal).
Different approaches to collecting FM data
In telecom environments, data collection approaches must accommodate the complexity of multi-vendor networks and diverse technology stacks commonly found in CSP infrastructures.
In this section, we briefly explore the different approaches of collecting fault management data. For a deeper dive into network monitoring techniques, check out our blog post on the types of network monitoring and their usage.
Active collection of fault management data
For simplicity, we've assumed a scenario where the network sends events to the fault management system. However, relying solely on network-initiated alarms has a significant pitfall. Fault conditions can often disrupt alarm generation. For example, a network fault can cause a part of the network to lose connectivity to the monitoring system. This is called a blind spot. All events generated from devices within the blind spot cannot reach their destination, making the monitoring system completely unaware of the problems that are currently present in the network.
Active collection of fault management data overcomes this issue. It involves the fault management system actively checking the status of devices, typically using ICMP, SNMP or some other network management protocol. The system inspects specific parameters and applies diagnostic rules to determine if a fault is present. Conversely, if the monitored device is unreachable by the monitoring system, it “knows” that something is wrong and an unreachable alarm is raised, thus overcoming a blind-spot problem.
Active fault management offers the advantage of detecting faults independent of the network's reporting mechanisms. However, it comes with drawbacks. Each device inspection consumes resources like CPU, memory of the monitoring system, and the device itself. Additionally, active methods involve periodic checks, introducing a delay before faults are detected. Therefore, deploying active fault management requires careful planning to avoid spending too many resources and to ensure timely detection of critical issues.

Passive collection of fault management data
Passive collection of fault management data is a push-based approach, where data is transmitted automatically by monitored devices, typically in the form of SNMP traps, SNMP Informs or syslog messages. Despite the limitations highlighted earlier, passive collection of fault management data remains a prevalent method today due to lower resource requirements for the monitoring system, the short delay between occurrence of a faulty state in the network and its representation in the monitoring system, and fast deployment.
Another push-based mechanism, which is relatively new and is gaining in popularity is called streaming telemetry. Network devices, such as routers, switches and firewalls, push health related data to a central location (usually Kafka streaming bus). Data can be transmitted at regularly configured intervals or when certain events occur (e.g., link down event). Even though streaming telemetry overcomes the limitations of SNMP protocol, it is still in its early stages and cannot be considered as a single approach for the collection of fault management data.
Hybrid approach
In real-world installations, none of the approaches mentioned can fully satisfy all the requirements. Therefore, a hybrid approach is commonly adopted, where both passive and active data collection methods are used in parallel, leveraging different protocols.
This approach is particularly essential in telecom networks where CSPs must ensure comprehensive coverage across diverse network domains including core, access, and transport networks.
For this reason, it is crucial that higher layers of a fault management system can process collected FM data regardless of protocols and the specific data collection method applied.
The Telecom Fault Management Process
The fault management process in telecom networks follows a structured approach tailored to meet the specific requirements of Communication Service Providers and their stringent operational standards. Collecting event data and generating alarms is the first step in the fault management process. It is followed by:
- Fault detection
- Fault location by alarm enrichment
- Alarm suppression to reduce alarm noise
- Alarm isolation: Correlation, Synthetic alarms, Root-cause analysis
- Restoration
- Fixing the problem
- The alarm lifecycle
1. Fault detection
Fault detection is the act of generating an alarm by filtering event data that indicates a faulty condition in the network and then mapping the data into an alarm. An alarm is simply an indication to engineers that there is something wrong. An alarm subsequently contains the exact same data that was provided by the event plus enriched data added by the fault management system itself.
Alarms are usually represented in the form of a table. The figure below displays how this looks in UMBOSS. Each row represents an alarm. As you can see, it is described by many parameters such as severity, source of alarm (agent), alarm raised (creation) time, last update time, description, etc.
In telecom environments, fault detection systems must be capable of processing thousands of alarms per minute while maintaining real-time performance to meet strict SLA requirements.
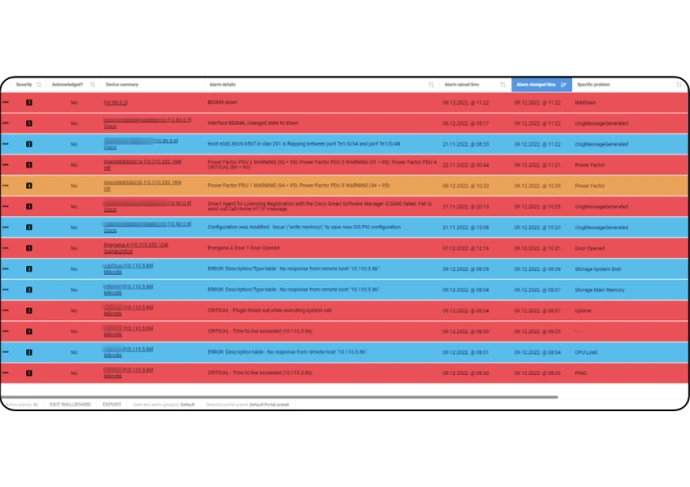
Example alarm dashboard
2. Fault location by alarm enrichment
When an active alarm appears, engineers need to start the isolation process. They need to know which device or devices are affected by the fault, where devices are physically or logically located, and what is causing the fault. It could be a malfunction of the device itself, or external conditions impacting the normal functioning of the network (e.g., cable cuts, power disturbances, high temperature, etc.).
For telecom operators, alarm enrichment becomes particularly critical as it must integrate data from multiple sources including network inventory systems, customer relationship management (CRM) platforms, and service provisioning databases to provide complete contextual information.
In landline communication networks, mobile networks, and data centers, an affected device’s location is information that is added to the alarm through the process of alarm enrichment. Alarm enrichment will add any data that cannot be provided within raw alarm data but is available in the fault management system.
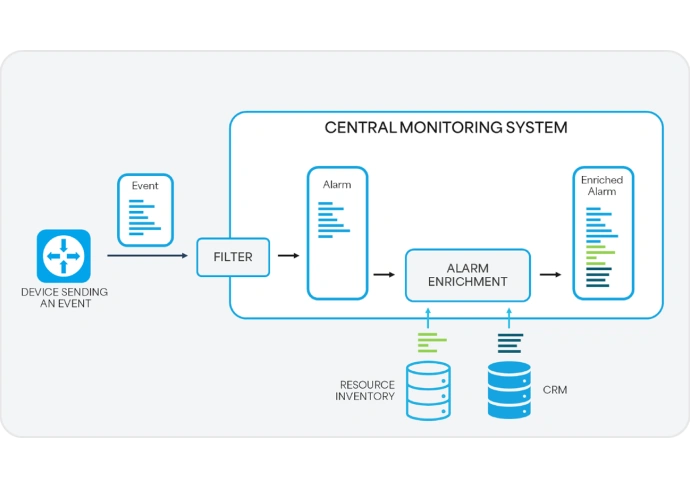
Alarm filtering and alarm enrichment process
The source of data for enrichment comes from external systems. This can include device data (from network inventory), device location, contact data, etc. In cases where there is a customer/user associated with a device (e.g., home router, CPE, or terminal), enrichment adds customer details and even service details to alarms, typically sourced from external CRM systems.
3. Alarm suppression to reduce alarm noise
Alarm suppression is particularly crucial in telecom networks, where operators struggle with alarm fatigue—internal audits often reveal that the majority of raw alarms (frequently 60–70 % or more) are duplicates or otherwise non-actionable, desensitizing staff and masking genuinely critical alerts.
Alarm suppression empowers network fault management systems to filter out alarms deemed unimportant by network engineers. A typical example involves alarms that occur due to planned network maintenance. Such alarms usually do not need to be displayed on the alarm dashboard; instead, they should be suppressed. To achieve this, network engineers provide advance notice of maintenance, defining the time frame for the work and the devices that will be affected. This information is sufficient for the fault management system to know which alarms to suppress and when. Once the maintenance is completed, any alarm that occurs from a device no longer covered by the suppression will be displayed normally.
Another common example involves alarms triggered when a telecommunications subscriber powers down their Customer Premises Equipment (CPE) during a predictable time window, such as a specific time of day or day of the week. While the CPE becoming unreachable technically constitutes a "faulty condition," it is considered normal and expected behavior in this scenario. Engineers can configure a rule for subscribers with this pattern, enabling the fault management system to automatically suppress these alarms. Consequently, the GUI can be configured to exclude these suppressed alarms from the displayed information.
4. Alarm isolation: Correlation, Synthetic alarms, Root-cause analysis
As mentioned earlier, a single fault can trigger hundreds or even thousands of alarms. This avalanche of alerts overwhelms engineers, making it difficult to identify the root cause and implement a fix. The process of pinpointing the origin is called alarm isolation.
Several mechanisms exist to aid in alarm isolation. One crucial mechanism is alarm correlation. Here's a relatable telecom example: imagine a sudden surge in alarms within a specific timeframe (e.g., 10 minutes) and geographic region (e.g., town or suburb). This indicates a problem in that region, easily detectable by a simple alarm correlation rule. Upon detection, a synthetic alarm is generated, replacing all individual alarms with a single one stating "massive outage in [town name]." This significantly aids engineers in isolating the issue to a specific location. Notably, the fault management system still allows for decomposing this synthetic alarm back to its constituent alarms for further analysis.
However, synthetic alarms might not be the ultimate solution. Network engineers often need to pinpoint the precise fault on a specific device that triggered the chain reaction. To address this, fault management systems employ root-cause analysis (RCA) mechanisms. RCA acts as a detective, sorting through the mess and identifying the actual network problem. Various algorithms, ranging from fixed rules and topology-based rules to advanced heuristic and AI/ML-based detections, power root-cause analysis.
The root cause is typically presented as an alarm, along with all contributing alarms. Engineers can always deconstruct this root-cause alarm to understand the reasoning behind its detection.
5. Restoration
In telecom operations, restoration procedures must align with strict SLA commitments and regulatory requirements, often requiring response times measured in minutes rather than hours.
After the fault management system has helped to isolate the fault (detect it), engineers must engage their restoration (assurance) procedures. The system helps them with executing assurance activities. Engineers may dispatch field technicians or change configurations to restore the service that was affected. Furthermore, some fault management systems may engage automated remedy actions that will restore the service. This can be as simple as trying to reset the device or interface remotely. After this, the system will clear alarms as the faulty condition can’t be detected any longer.
Therefore, a fault management system that allows engineers to efficiently engage their restoration assurance procedures or even engage automated remedy procedures is a true network assurance system.
6. Fixing the problem
After restoring service, engineers prioritize identifying the root cause of the fault—the actual problem. It could be a software glitch fixable with an upgrade or even a design flaw.
Analysis includes log reviews, inventory checks, and various procedures. The solution might be as simple as the initial fix – for instance, repairing a cable cut by construction workers.
However, service restoration might not solve the underlying problem. If a device was simply plugged back in, it could become unplugged again. This suggests a design flaw.
A permanent fix requires an assurance procedure, like installing and testing a dedicated power cable.
The fault management system remains crucial here. Its historical data aids in identifying repetitive faults through reports (e.g., top N outage reports) or even advanced analytics (statistical or ML-based) to pinpoint the root cause of recurring network issues.
7. The alarm lifecycle
The alarm life cycle in fault management systems involves several stages. It begins with the “birth of an alarm” which signifies the moment when a specific event or network fault occurs, resulting in the creation of an alarm. Next, the system classifies the alarm based on its severity and impact. During the presentation stage, the alarm is displayed to network engineers, and can change its parameters like state, severity, priority, description, etc. During this stage the majority of alarm management activities are executed either automatically or manually by network engineers. After resolution, the alarm enters the clearance stage, where it is usually removed from the alarm dashboard. Finally, the system archives the alarm data for historical analysis and reporting.
One important descriptor of an alarm is its severity. Severity level is determined by the device when it generates event data when its status is changed. It is either a number or description (e.g., clear, intermediate, warning, minor, major, critical).
A faulty device generates new events when a situation changes and notifications are sent to the fault management system to reflect this change. This may change the alarm’s status (e.g., the severity level) and the fault management system will indicate this change in the alarm dashboard. Each update of alarm information (triggered by an event) usually increases the alarm parameter that is called “tally”. The larger the tally is, the more things that are happening with the fault during an alarm’s lifetime.
Engineers routinely set the state of an alarm to “acknowledged” to indicate that they are aware of the faulty condition. Acknowledging an alarm is just one possible response. Others may include accessing a knowledge database, accessing an external system, and changing the alarm’s severity, among many others.
Fault management systems also keep a detailed journal of each alarm. An alarm journal is a chronological record that stores all changes or actions relevant to a single alarm, including their timestamps, user details, descriptions, etc. An alarm journal is crucial for network engineers since it enables post-incident analysis and better reporting capabilities.
It is important that any fault management system has the capability to open a ticket in a ticketing (ITSM) tool. The ticket will receive parameters depending on the type of integration with the ticketing system. For instance, an alarm can open a ticket in a call center so that impacted customers can be informed about the situation. Another example is opening a ticket for field technicians to take appropriate action.

Key Challenges in Network Fault Management in Telecom
Telecom operators face increasingly complex challenges in network fault management as they transition to software-defined infrastructures, deploy 5G networks, and manage multi-vendor environments at unprecedented scale.
Challenge 1: Multi-Vendor Complexity
One of the most significant challenges facing telecom operators today is managing fault data across multi-vendor network environments. Modern telecom networks typically involve equipment from multiple vendors, each with proprietary protocols, management interfaces, and data formats. The complexity increases exponentially as CSPs integrate legacy systems with modern SDN and NFV technologies, often requiring complex API integrations and support for legacy protocols like CORBA.
Integration challenges arise when vendors use diverse proprietary standards that decrease interoperability and make seamless operation difficult. The more vendors involved in the network infrastructure, the more complex the fault management becomes, requiring specialized expertise and custom integration solutions.
Challenge 2: Alarm Fatigue
Alarm fatigue represents a critical operational challenge where network engineers become desensitized to alarm notifications due to excessive false positives and redundant alerts.
In telecom operations, where engineers may handle thousands of alarms daily, this desensitization can result in missed critical alerts that impact service availability and customer experience.
Challenge 3: SLA Penalties and Compliance
Telecom operators are subject to stringent regulatory requirements and detailed SLAs that define key metrics such as network availability, latency, and packet loss. Failure to meet these contractual targets typically triggers service-credit rebates or fee reductions, often structured on a sliding scale against the monthly service fee rather than a flat daily penalty . Repeated or severe SLA violations can also draw regulatory scrutiny or fines in jurisdictions that mandate minimum telecom quality standards.
The financial repercussions of SLA violations go well beyond immediate service‐credit rebates, driving higher customer churn, closer regulatory scrutiny, and—even in extreme cases—threats to operating licenses. Moreover, the cost of unplanned network downtime is substantial: Gartner’s research indicates that unplanned network downtime can be extremely expensive for enterprises, with losses escalating rapidly during major outages.
Challenge 4: NFV/5G Complexity
The deployment of Network Function Virtualization (NFV) and 5G technologies introduces new layers of complexity in fault management that traditional rule-based systems cannot effectively handle. Virtualized network functions create complex interdependencies between virtual machines, hypervisors, and underlying hardware that require sophisticated monitoring and correlation capabilities.
5G networks with their software-defined nature and network slicing capabilities require fault management systems that can handle dynamic service provisioning and real-time performance optimization. The combination of SDN and NFV in 5G networks results in generic hardware running multiple software functions, making fault isolation and root cause analysis significantly more challenging.
Challenge 5: Scalability and Real-time Requirements
Modern telecom networks require fault management systems that can process and correlate massive volumes of alarm data in real-time while maintaining sub-second response times. Traditional fault management approaches struggle with the scale and velocity of data generated by modern telecom infrastructures, particularly in 5G and IoT environments.
The need for real-time fault detection and automated remediation becomes critical as telecom operators face increasing customer expectations for always-on connectivity and zero-tolerance for service interruptions. AI-native fault management systems are becoming essential for predictive analytics and automated troubleshooting to meet these demanding requirements.
Implementing an Effective Fault Management Strategy in Telecom Networks
Building a comprehensive fault-management strategy for telecom networks requires aligning with industry-specific operational needs, meeting regulatory quality mandates, and fulfilling customer SLA commitments.
Fault management strategy involves implementing the right fault detection and isolation techniques, automated remediation techniques, methods of preventing or minimizing future faults, as well as choosing the right software for network fault management solutions.
Best Practices for Network Fault Detection and Isolation
The best practices for network fault detection largely depend on the network setup you have. Unified network infrastructure is the simplest case. It is a well-tested environment for which one usually uses a well-balanced combination of active and passive fault management. When possible, streaming telemetry is a great option.
However, telecom networks are typically complex, hybrid environments spanning multiple technology domains including IP/MPLS, SD-WAN, DWDM, optical transport, and wireless access networks.
Large network setups are usually a hybrid of different technologies like IP/MPLS, SD-WAN, DWDM, etc., and even power supply, access management systems, HVAC, and other elements that also participate in the network’s health. Very often, each of these segments is managed by respective element management systems (EMSs). Therefore, to detect faults in the network, one must be able to collect events from all these segments. Besides classical event collection from network devices, one must integrate with all EMS systems involved to ensure all network elements are being monitored. This involves building integration points that range from simple passive SNMP and syslog event collection to complex API-based integrations, often including legacy integration technologies like CORBA.
This consolidation-based approach pays off because proper fault isolation then becomes a reality. Correlation or root-cause analysis of alarms from different segments (often referred to as domains) can pinpoint the problem by analyzing complex relationships between network elements in various domains. Moreover, one can correlate alarms from network elements and power systems as these two are often very much interrelated. The importance of enriching alarms with inventory and other non-technical data cannot be overstated, as these are key to adding context and which correlation and RCA mechanisms revolve.
In telecom environments, this approach becomes essential for managing the complexity of multi-vendor networks where different equipment suppliers use proprietary protocols and management interfaces.
In the end, aggregating alarms from all sources could lead to displaying a large number of alarms. Therefore, it is crucial that the software used for fault management has powerful mechanisms to prevent false-positive alarms from being displayed and ensure that network engineers only see actionable alarms enriched with all relevant data needed for fast and efficient troubleshooting.
Utilizing Automation in Fault Management
Automation in telecom fault management is not just an operational efficiency tool but a business necessity for maintaining competitive service levels and reducing operational costs. Automation of fault management is key for efficient and successful assurance of your whole network. When we say automation, it means several things that work in the same direction:
- Automatic triggering of external processes: This means that the fault management system will, upon isolating a fault by means of correlation or RCA, automatically invoke a process in an external process management system. This can be as simple as opening a ticket in an ITSM tool or initiating a more complex process in a workforce orchestration engine.
- Automatic remediation: This means that the fault management system will trigger an orchestrated set of actions that involve reprovisioning or reconfiguring network elements or restarting certain elements or functions of the network to temporarily or permanently fix the problem. In telecom networks, automation can include automatic service restoration, dynamic traffic rerouting, and predictive maintenance scheduling based on fault pattern analysis.
Depending on the actual implementation, automation can combine these approaches to provide a coordinated set of actions that involve human manual intervention, remote or on-site, as well as automated remediation actions.
Correct implementation of automation can reduce the number of human interventions by over 50% and practically eliminate human errors that occur during the troubleshooting process. At the same time, the response time to the occurrence of specific network faults is minimized, significantly enhancing the overall quality of services provided to end users. Indirectly, end users are more satisfied since a large number of network issues that used to take much longer to resolve are now addressed very quickly.
Proactive Measures to Prevent Future Faults
The ultimate goal of fault management is to prevent network faults from occurring. While it’s not possible to proactively react to every conceivable situation, many network faults are influenced by external factors such as human mistakes, construction work, faults in power facilities, weather conditions, and natural disasters. However, the goal of effective fault management is to proactively respond to everything that is feasible. There are two approaches combined to achieve this goal:
- Detecting pending faults: The fault management system uses event analysis and a set of algorithms to predict faults that may occur in the network. This can involve the use of ML-based pattern recognition on events for scenarios where a specific set of events precedes alarms. This is closely related to the observability function, which will be described in more detail in one of our upcoming blog articles. This can warn engineers to prepare for pending faults and hopefully prevent them from happening in the first place.
- Preventive problem resolution: This involves using historical data in the fault management system to detect the elements of the network that are likely to cause some problem in the network. Engineers can use so-called Top-N reports that contain the list of devices or components with the highest rate of faults. Other types of reports can also be useful. For example, if the expected lifetime of a power supply is 3 years, the report can give us the list of all power supplies older than 3 years, so that power supplies can be preventively replaced before an outage occurs. There are plenty of similar reports that help engineers plan their replacement or apply fixes that will completely remove the pending problem. This is closely related to network maintenance and planning activities.
For telecom operators, proactive fault prevention directly impacts MTBF (Mean Time Between Failures) metrics and helps maintain the high availability standards required for regulatory compliance and customer satisfaction.

The Connection Between Fault Management, Network Monitoring and Network Performance Management
Fault management and performance management are the two pillars of network management. Although they seemingly address two different aspects of the network’s health, they are very much related and interdependent. Performance management directly impacts faults in the network, and we can use an example to illustrate how.
Imagine a data center with limited cooling capacity. If everything is properly dimensioned, the temperature will stay at the designed level, allowing all devices to run smoothly. However, if data center staff start adding new devices without control, it will result in a steady increase in temperature. This will increase the chance of certain devices or their components failing, thus causing faults in the system. Performance management’s primary task is to provide an indication that the temperature is rising above designed thresholds and warn engineers about the potential threat. Responsible engineering teams will react by adding more cooling capacity or simply preventing the addition of new devices, thus avoiding any faults in the system.
This is only one of many examples of how performance management directly impacts fault prevention by providing the means to optimize network operation in a way that prevents future problems. You can learn more about performance management in our blog postNetwork Performance Management (NPM) Explained.
In telecom networks, the integration between fault management and performance management becomes even more critical as operators must maintain strict QoE standards while optimizing network resources and capacity utilization.
Benefits of a Network Fault Management in Telecom
The benefits of implementing comprehensive network fault management in telecom environments extend far beyond basic network monitoring, directly impacting both operational efficiency and business performance for Communication Service Providers.
We can finally summarize the key benefits of a fault management system. There are operational arguments that can be used by any manager to explain why this element is a must for every IT or telecom organization (technical benefits), however fault management provides even more business benefits for an organization.
Technical benefits
- Essential visibility over network health, without which there is no way to guarantee any digital service for users/subscribers.
- A unified fault-management platform provides a real-time window into the status of every network element—without it, there’s no way to guarantee that services are running correctly or to detect emerging issues before they impact users
- Fault detection, isolation, and fast reaction to any problem.
- By filtering and correlating events into actionable alarms, operators can pinpoint and resolve faults rapidly, minimizing mean time to repair (MTTR) and avoiding prolonged outages
- Preventing future faults.
- Analytics and Top-N reporting highlight recurring or aging components, enabling proactive maintenance that raises mean time between failures (MTBF) and reduces unscheduled downtime
- The key tool for problem resolution and network renewal/redesign planning.
- Historical alarm journals and RCA reports inform capacity planning, topology optimizations, and design changes to eliminate systemic failure points.
- Management and daily operational reporting.
- Dashboards and automated reports deliver the KPIs managers need—uptime, alarm counts, MTTR, fault trends—so teams can track performance against SLAs and regulatory requirements
Business benefits
- Revenue Protection: Minimizing network downtime ensures that revenue-generating activities are not interrupted, protecting the organization’s bottom line and minimizing network operation costs. For telecom operators, unplanned downtime can cost thousands of dollars per minute (Gartner’s mid-2010s average was $5,600/minute) and—even without quoting an exact “up to”—major, prolonged outages can easily translate to multi-million-dollar impacts when you include lost service revenue, SLA credits, and reputational damage
- Cost Efficiency: By detecting and resolving network issues before they escalate, fault management minimizes unplanned expenses and stabilizes IT budgets. In practice, automation and faster MTTR can reduce manual interventions by 40–60 %, delivering significant operational-expense savings and more predictable cost planning
- Brand Reputation: A reliable and stable network supports consistent service delivery, enhancing customer satisfaction and protecting the company’s reputation. In the competitive telecom market, network reliability directly impacts customer churn rates and brand perception.
- Customer Retention: Ensuring service excellence and great user experiences helps retain customers and reduce churn. Telecom operators may find themselves facing significant revenue losses each time a service disruption affects customer experience.
- Employee Productivity: A stable network supports efficient workflows and collaboration, boosting overall employee productivity.
- Operational Efficiency: Streamlined network operations reduce the burden on IT staff, allowing them to focus on strategic initiatives rather than firefighting.
- Risk Management: Proactive monitoring helps identify and mitigate risks, ensuring business continuity and compliance with regulatory requirements. For telecom operators, this includes maintaining compliance with strict regulatory frameworks that mandate service reliability standards.
- Data-Driven Marketing: Network monitoring provides valuable data that can be used to optimize marketing campaigns and improve customer targeting.
- Competitive Advantage: A robust network allows for the deployment of innovative services and faster time-to-market, giving the company a competitive edge.
- Strategic Planning: Insights from network monitoring can inform strategic decisions, such as when to invest in new technologies or expand infrastructure.
- Monetization: Telecom operators can monetize fault management systems by offering proactive monitoring services with special SLAs, guaranteeing metrics like uptime and latency. This enhances customer satisfaction and justifies premium pricing. This creates additional revenue and strengthens relationships with enterprise customers through reliable infrastructure management.
UMBOSS & Fault Management
UMBOSS is a software product that incorporates a fault management system as its key element. The UMBOSS event and fault management module (UMBOSS EFM) collects and stores all events and alarms from all underlying network elements, element management systems (EMSs), and network management systems (NMSs). This makes UMBOSS a fault consolidation platform.
For telecom operators, UMBOSS offers specialized features including CSP-focused alarm correlation, telecom-specific enrichment capabilities, and integration with BSS/OSS systems commonly used in telecommunications environments.
Due to the fact that UMBOSS also enriches alarms with non-technical data and provides a 360-degree view of network health, it is a perfect solution for implementing an umbrella approach in fault management and network management in general.
UMBOSS supports telecom-specific protocols and standards, enabling seamless integration with existing telecom infrastructure while providing the scalability and real-time performance required for modern CSP operations.
Have any questions? Want to learn more? Get in touch and let us know how we can help. Send us a message or book a demo today.
Frequently Asked Questions (FAQ)
What are the common types of faults and issues in telecom network management?
The most common fault types in telecom networks include hardware failures due to aging equipment and environmental factors, software bugs in network functions and firmware, and configuration errors during provisioning or maintenance activities. Additionally, external factors such as power outages, cable cuts, and environmental conditions frequently impact network operations.
What is the impact of network faults on user experience and business operations in general?
Network faults directly degrade Quality of Experience (QoE) through service interruptions, latency increases, and call drops, leading to customer dissatisfaction and potential churn. From a business perspective, faults result in immediate revenue loss, SLA penalty costs, and long-term brand reputation damage that affects customer acquisition and retention.
What is The Future of Network Fault Management in Telecom?
The future of telecom fault management lies in AI-native systems that leverage machine learning for predictive analytics, automated root cause analysis, and self-healing network capabilities. These systems will enable proactive fault prevention, real-time automated remediation, and intelligent alarm correlation to meet the demanding requirements of 5G and future network technologies.
Fault Management vs. Performance Management
Fault management focuses on detecting, isolating, and resolving network problems when they occur, while performance management continuously monitors QoS metrics and network utilization to optimize overall network performance. Both disciplines are complementary and interdependent, with performance management providing early warning indicators that help prevent faults from occurring.









